Kanooniline korrespondentsanalüüs (lühendid CA, CCA)
NB! Selle lehekülje käsud on eriti tähtsad iseseisva kodutöö tegemiseks. Kopeeri need järjest oma programmi.
Kasutame andmeid zoopl_aug2.csv baasil moodustatud liikide andmetabelit, kus rida oli koht ja veerg on liik.
andmed<-read.csv("zoopl_aug2.csv", header=T)
andmed[is.na(andmed)] <- 0
attach(andmed)
zoo2<-andmed[,-c(1,2,3)]
ord <- cca(zoo2,scale=T)
#Kanoonilise analüüsi kokkuvõte
summary(ord)
Väljatrükk lühendatult, ainult olulised osad:
Call:
cca(X = zoo, scale = T)
Eigenvalues, and their contribution to the mean squared contingency coefficient
Importance of components:
CA1 CA2 CA3 CA4 ....
Eigenvalue 0.524 0.424 0.265 0.213 ....
Proportion Explained 0.250 0.202 0.126 0.102 ....
Cumulative Proportion 0.250 0.452 0.578 0.680 .... # kirjeldusvõime, kui *100, siis %
Kumulatiivne %, mille 2 peakomponenti hajuvusest kirjeldavad, on 45.
Scaling 2 for species and site scores
* Species are scaled proportional to eigenvalues
* Sites are unscaled: weighted dispersion equal on all dimensions
Species scores
CA1 CA2 CA3 CA4 CA5 CA6
L1 1.516593 0.87913 0.11661 -0.731658 0.01797 -0.254412
L2 -0.463163 -0.16148 -0.54511 -0.365262 0.12764 -0.166996
L3 -0.290070 -0.37826 -0.30034 0.142045 0.10059 0.508301
L4 0.436062 0.21733 0.06854 -0.682400 2.67274 -0.315764
..................................................................................................................
jne kuni viimase liigini, samuti skoorid kõikide kohtade jaoks.
Neid skoore kasutatakse järgneva joonise tegemisel, pane tähele tellimise juures, kuidas tellitakse liigid, kuidas kohad.
Kasutame andmeid zoopl_aug2.csv baasil moodustatud liikide andmetabelit, kus rida oli koht ja veerg on liik.
andmed<-read.csv("zoopl_aug2.csv", header=T)
andmed[is.na(andmed)] <- 0
attach(andmed)
zoo2<-andmed[,-c(1,2,3)]
ord <- cca(zoo2,scale=T)
#Kanoonilise analüüsi kokkuvõte
summary(ord)
Väljatrükk lühendatult, ainult olulised osad:
Call:
cca(X = zoo, scale = T)
Eigenvalues, and their contribution to the mean squared contingency coefficient
Importance of components:
CA1 CA2 CA3 CA4 ....
Eigenvalue 0.524 0.424 0.265 0.213 ....
Proportion Explained 0.250 0.202 0.126 0.102 ....
Cumulative Proportion 0.250 0.452 0.578 0.680 .... # kirjeldusvõime, kui *100, siis %
Kumulatiivne %, mille 2 peakomponenti hajuvusest kirjeldavad, on 45.
Scaling 2 for species and site scores
* Species are scaled proportional to eigenvalues
* Sites are unscaled: weighted dispersion equal on all dimensions
Species scores
CA1 CA2 CA3 CA4 CA5 CA6
L1 1.516593 0.87913 0.11661 -0.731658 0.01797 -0.254412
L2 -0.463163 -0.16148 -0.54511 -0.365262 0.12764 -0.166996
L3 -0.290070 -0.37826 -0.30034 0.142045 0.10059 0.508301
L4 0.436062 0.21733 0.06854 -0.682400 2.67274 -0.315764
..................................................................................................................
jne kuni viimase liigini, samuti skoorid kõikide kohtade jaoks.
Neid skoore kasutatakse järgneva joonise tegemisel, pane tähele tellimise juures, kuidas tellitakse liigid, kuidas kohad.
Joonised
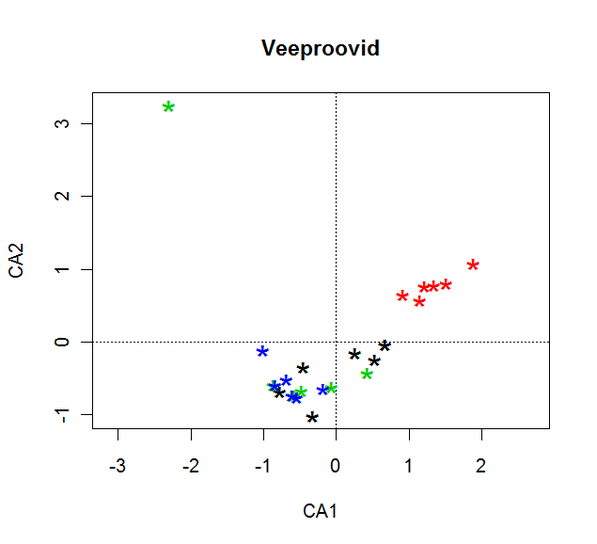
plot(ord, type = "n") #jätame punktid esialgu peale kandmata
points(ord, display = "sites", col = as.numeric(osa), pch="*", cex=2)
#värvide järjekord vastavalt järveosade numbritele: must, punane, roheline, sinine). Kuna erinevatest järveosadest oli mõõtmisi mitmel aastal ja mitmest punktist, siis ülaltoodud graafikul eristan järveosad eri värvidega, näha on teise järveosa eristumine.
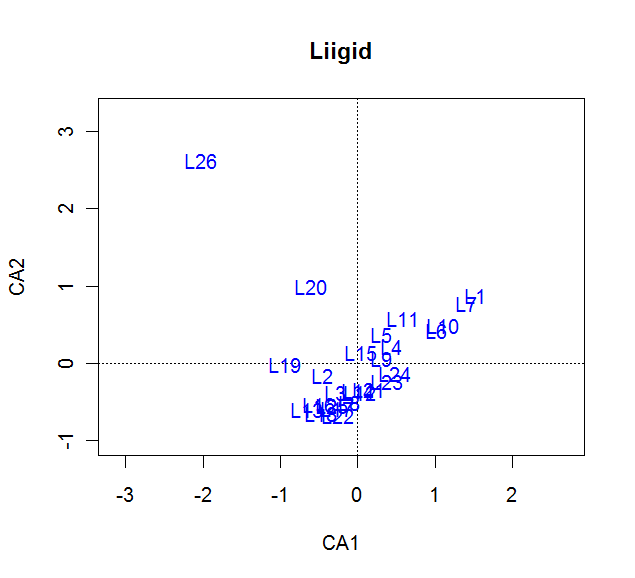
Eelneva joonise kood:
plot(ord, type = "n",main="Liigid")
text(ord, "species", col="blue", cex=1) # liikide nimed õigetel kohtadel
Liikide osas ei ole gruppe eriti hästi võimalik eristada, mõned eraldiseisvad liigis paistavad siiski välja. Peab mainima, et kui ordineerimine olulist efekti ei too (peakomponendid ei kirjelda hajuvust hästi), või kui liike või kohti on veel rohkem kui praegu, siis ongi ordineerimismeetodite graafikud sama loetamatud, kus nimed paiknevad üksteise peal.
plot(ord, type = "n",main="Liigid")
text(ord, "species", col="blue", cex=1) # liikide nimed õigetel kohtadel
Liikide osas ei ole gruppe eriti hästi võimalik eristada, mõned eraldiseisvad liigis paistavad siiski välja. Peab mainima, et kui ordineerimine olulist efekti ei too (peakomponendid ei kirjelda hajuvust hästi), või kui liike või kohti on veel rohkem kui praegu, siis ongi ordineerimismeetodite graafikud sama loetamatud, kus nimed paiknevad üksteise peal.
Liigid ja kohad on võimalik paigutada ka samale graafikule, kasutades point ja text käske, taoline joonis aga muutub kahjuks veel arusaamatumaks.
ISESEISEV KODUNE TÖÖ. Juhend
