k-keskmiste meetod
Vastav R help lehekülg
Tavapärane andmete ettevalmistamine:
andmed<-read.csv("Zoopl_aug2.csv", header=T)
andmed[is.na(andmed)] <- 0
attach(andmed)
zoo<-andmed[,-c(1,2,3)]
names(andmed)
d1 <- scale(zoo)
Siit alates rühmitamise osa - jagame vaatlused näiteks kolme gruppi, minu hüpotees on, et mingid 2 järveosa peaksid olema omavahel sarnased.kmeans funktsiooni parameetrid on skaleeritud liikide arvukuste maatriks, soovitud klastrite arv ja juhuslike valikute arv valimist, mis on vajalikud rühmade keskmistamise jaoks. Valida saab erinevaid algoritme.
cl <- kmeans(d1, 3, nstart = 25)
# lisame klastri numbri algandmetele kõrvale
cbind(andmed,cl$cluster)
Leiame sagedustabelid vastavalt järveosade ja aastate jaoks, kuidas vaatlused jagunevad klastrite vahel
table(osa,cl$cluster)
table(aasta,cl$cluster)
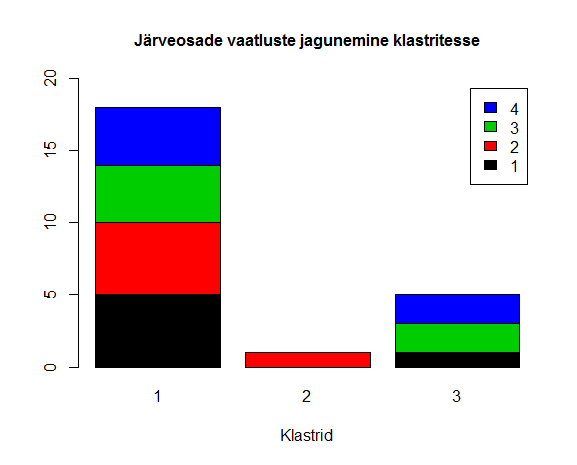
Sagedustabelid näitavad meile, missugused järveosad või aastad samadesse klastritesse sattusid.
Vaatame sagedustabeli põhjal tehtud tulpdiagrammi. Järveosad on eri värvidega tähistatud. Selge on, et klastritesse jagunemise aluseks ei ole järveosad kindlasti mitte.
barplot(table(osa,cl$cluster),legend=T,col=1:4, ylim=c(0,20),xlab="Klastrid",
main="Järveosade vaatluste jagunemine klastritesse",cex.main=1)